School of computer science
Georgia Institute of Technology
CS6290HPCA Fall 2009
Programming assignment #2
Due: Wednesday, Nov 4 6:00 pm Monday, Nov 2 6:00 pm Friday, October 30, 6:00 pm
Hyesoon Kim, Instructor
This is an individual assignment. You can discuss this assignment with other classmates but you should do your assignment individually. Please follow the submission instructions. If you do not follow the submission file names, you will not receive the full credit. Please check the class homepage to see the latest update. Your code must run on killerbee[1-5].cc.gatech.edu with g++4.1.
Overview
This assignment is composed of two parts: Part 1: building the simulator, Part 2: simulation and analysis (option)
Part 1(100 pts): Building a Superscalar processor
In this assignment, you will improve your pipeline design to have (1) branch predictor and (2) Superscalar and (3) Tomasulo's algorithm (register renaming and out of
order scheduling). You will extend your Lab #1 pipeline design. We provide add_me.txt file is provided. Please add the code at appropriate places. userknob.h and simknob.h files are updated. Please download the new files.
(1) Implement a g-share branch predictor
Add a g-share branch predictor in the FE stage. When a processor fetches a conditional branch instruction (cf_type must be CF_CBR), it accesses the branch predictor. If a branch is mispredicted, the processor should not fetch instructions from a correct path. i.e., the processor should not call the get_op function. Instead, it should stall the pipeline until the branch instruction is resolved. After the branch is resolved, in the next cycle the correct PC address is forward to the PC latch. From the following cycle the processor can start to fetch instructions from the correct path. Note that in a real hardware, the processor will keep fetching wrong path instructions until a branch is resolved. Once a misprediction is discovered, the processor flushes the pipeline and starts to fetch instructions from the correct path. Since we are building a trace-driven simulator, we cannot send wrong-path instructions into the pipeline. That's why we are stalling the pipeline to model the time delay between a branch prediction and branch resolution.
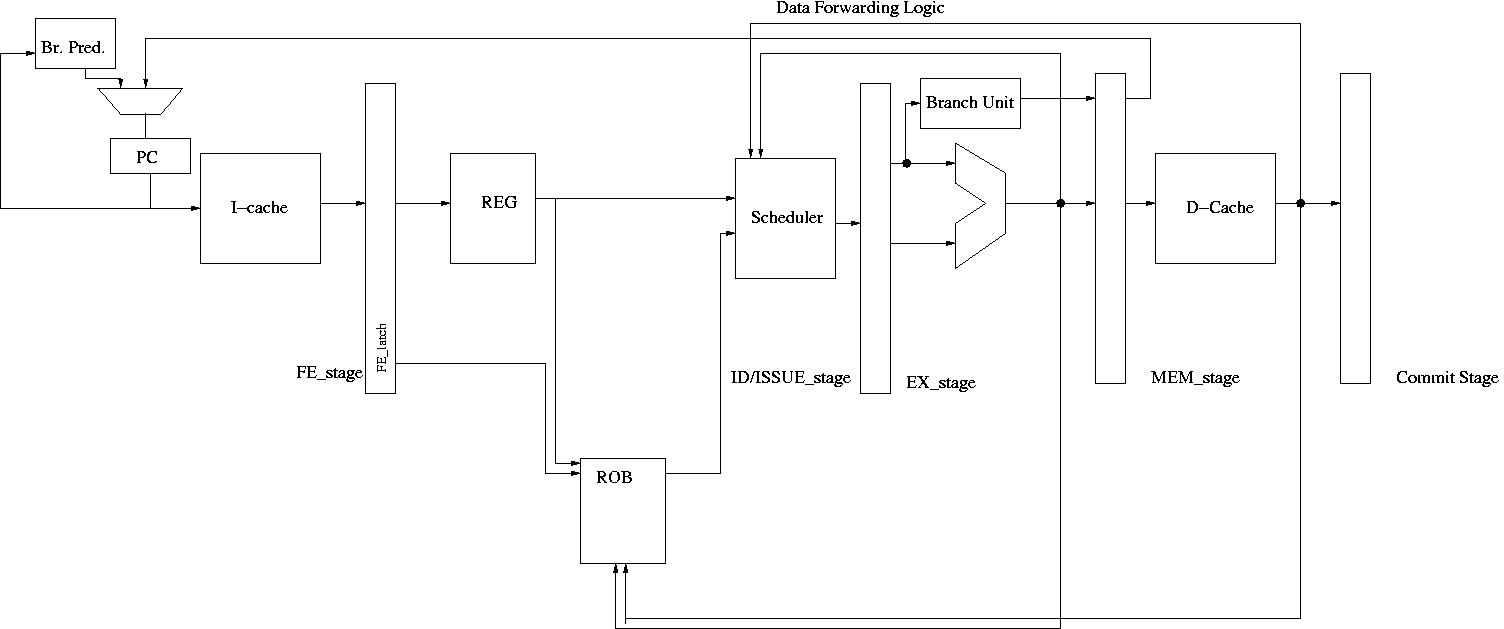
pipeline design
(2) a superscalar processor.
Now you extend your simulator to handle more than one instruction at a
cycle. It can fetch/decode/execute/retire "KNOB_ISSUE_WIDTH" number of
instructions. Fetch, decode, retire must be in order. We assume that
the pipeline has "KNOB_ISSUE_WIDTH" number of functional units.
All functional units are pipelined.
(3) Tomasulo's algorithm
Instructions will be renamed and instructions can be executed out of
order. Instructions must be retired in order. To implement an out of
order processor, you need a scheduler in the pipeline. To support an
in-order retirement, there is a ROB. After an instruction is decoded
at the beginning of the ID stage, if there is an available slot in the
scheduler, the processor sends the instruction into the
scheduler. Ready Instructions (all the source values are ready) in the
scheduler can be executed at the following cycle. You must provide the
feature of executing instructions in-order also.
Rob and scheduler
The scheduler size is determined by KNOB_SCHED_SIZE. The processor can send up to KNOB_ISSUE_WIDTH instructions into functional units (i.e., the processor can schedule up to KNOB_ISSUE_WIDTH instructions).
You also need to implement a ROB. At ID_stage, an instruction is sent to the ROB regardless of whether sources are ready or not. If there is no space in the ROB, the fetch stage must stall. Instructions are removed from the ROB at the commit stage.
Data forwarding
An instruction becomes eligible for execution in the cycle that follows the one in which the last operand was forward from either EX stage or MEM stage. There are data forwarding paths from EX stage and MEM stage.
KNOBS
New KNOBS
KNOB_ROB_SIZE: it sets the number of entries in the Rob (default value is 64)
KNOB_SCHED_SIZE: it sets the number of entries in the scheduler (default value is 8)
KNOB_OOO_SCHEDULER: It sets the scheduling policy. ( 0: in order scheduling 1: out of order scheduling)
KNOB_GHR_LENGTH: It decides the length of GHR. The number of gshare predictor entry is 2^(KNOB_GHR_LENGTH).
KNOB_DEBUG_PRINT: print a debug message. (0: no debug message 1: print debug message )
KNOB_ISSUE_WIDTH: It sets the number of fetch/decode/issue/schedule/execute/retire width
KNOBS from Assignment #1
KNOB_OUTPUT_FILE: set the output filename of the print_stats function
KNOB_TRACE_NAME: set the input trace file name
KNOB_READ_TRACE: (1): read trace and execute the simulator (0): execute the binary
You should not set 1 for both KNOB_WRITE_TRACE and KNOB_READ_TRACE. Only one of them has to be 1.
KNOB_MAX_SIM_COUNT: set the maximum cycle_count for the simulation
KNOB_MAX_INST_COUNT: set the maximum inst_count for the simulation
KNOB_PRINIT_PIPE_FREQ: set the frequency of calling print_pipeline() function
Grading
We will check branch predictor accuracies as we vary the length of GHR.
We will check IPC values to grade your homework. We will vary issue width.
We will also use the KNOB_DEBUG_PRINT knob to check in-order/OOO scheduling and in-order retirement. You must replace print_stats() function with the new one at add_me.txt file.
Please make it sure your simulation can be ended until the end of traces and remove all debug statements that you added.
Submission Guide
Please do not turn in pzip files(trace files). Trace file sizes are so huge so they will cause a lot of problems.
(Tar the lab2 directory. Gzip the tarfile and submit lab2.tar.gz file at T-square)
cd pin-2.6-27887-gcc.4.0.0-ia32_intel64-linux/source/tools
cd lab2
make clean
rm *.pzip
cd ..
tar cvf lab2.tar lab2
gzip lab2.tar
Please do not let your zombie jobs use all the machine resources!!
Note: Assignment #2 is significantly longer than Assignment #1. Please start early.
Part 2 extra (additional) 20 pts: Simulation and analysis
Due: 11/3/09 before class. Hard copy only
Using your simulator, you will do performance analysis. You will generate traces which are at least longer than 10,000 instructions. Any applications are fine. Please do not turn in your traces!!
Include your simulation results in the report. The default configurations are
gshare history length: 8
issue width: 2
out of order scheduler
ROB size: 64
- Vary the issue width from 1 to 3 (1, 2 and 3) and discuss performance impacts. Test both in order scheduling and out of order scheduling mechanisms. Discuss how the performance improvements are different.
(Hint: why (IPC (width=2) - IPC(width=1)) >> (IPC(width=3) - IPC(width=2)) ? )
- Write two simple benchmarks that could have different branch prediction accuracies. Differences should be more than 5%. You could use existing benchmarks.
Simple floating point benchmarks such as matrix multiplications, PDE calculations typically have high branch prediction accuracy and complicated benchmarks such as bzip2, the simulator itself would have high branch misprediction rate.
Demonstrate the performance as you vary gshare history length (4,8,12).