
This assignment has 4 problems:
A. [3 points]
Regardless of whether we use a conservative approach or branch prediction
("branch not taken"), explain why there is always a 2-cycle delay if the branch is taken
(i.e., 2 NOPs injected into the pipeline) before normal execution can resume
in the 5-stage pipeline below.
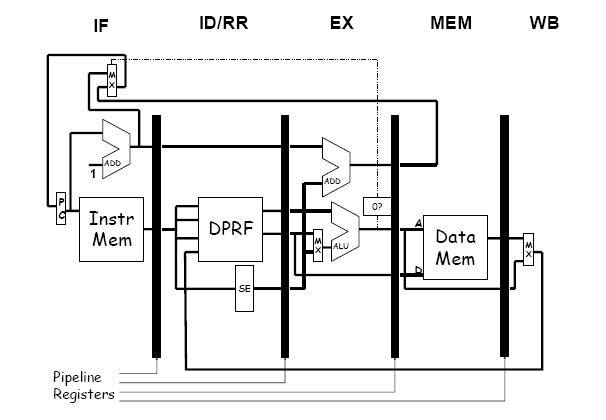
This pipeline is the one discussed in Chapter 5 of your textbook (see Section 5.13.3).
B. [3 points]
With reference to the figure below, identify and explain the role of the datapath
elements that deal with the BEQ instruction. Explain in detail what exactly happens
cycle by cycle with respect to this datapath during the passage of a BEQ instruction.
Assume a conservative approach to handling the control hazard.
Your answer should include both the cases of branch taken and branch not taken.
For all the different parts of this question, use a 5-stage pipeline similar to what has been discussed in class and described in Chapter 5. Specific to this question assume the following:
As a reminder, the LC-2200-16 has the following characteristics:
Consider the following code fragment that increments the elements of an array stored in memory. At the entry to the fragment, register $a0 contains the address of the array of words and $a1 is equal to $a0 plus the length of the array in bytes.
loop: LW $t0, 0($a0)
ADD $t0, $a0, $t0
SW $t0, 0($a0)
ADDI $a0, $a0, 1
BEQ $a1, $a0, done
NOP
BEQ $zero, $zero, loop
NOP
done: HALT
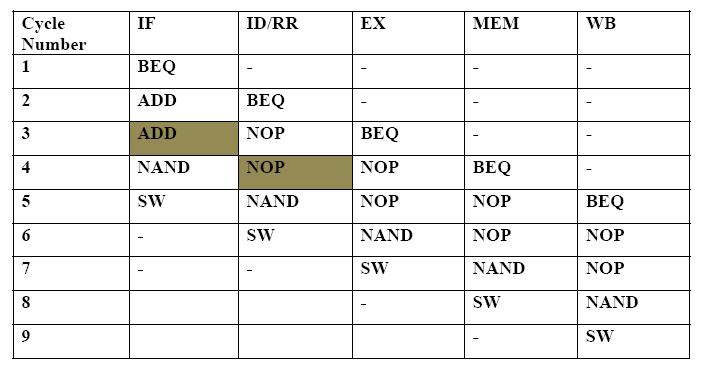
A. [7 points] Simulate the state of the pipeline for 15 cycles and show which instruction is in each stage at each cycle. Use one line per cycle and one column per stage. Note that we do not know what was in the pipeline before the first ADDI instruction but assume whatever it is causes no stalls. Also assume that the first branch is not taken for several iterations. Here's an example format:
Stage
Cycle IF ID EX MEM WB
----- -- -- -- --- --
1 LW ? ? ? ?
2
3
4
5
6
7
8
9
10
11
12
13
14
15
B. [3 points]
C. [4 points]
Identify how many of each type of hazard are in the code fragment above.
D. [4 points]
Re-write the code fragment to remove as many hazards as possible while
trying to increase efficiency as well (NOTE: You may not be able to remove
all the hazards). This does not mean that you should litter the
code segments with nops.
(HINT: just because there is a delay slot doesn't mean
a nop needs to be there; see Section 5.13.3 of the textbook).
A. [22 points] Consider the following set of processes, with the length of the CPU-burst time given in milliseconds.
Process Burst Time Priority ------- ---------- -------- P1 5 1 P2 4 5 P3 6 4 P4 3 2 P5 1 3
The processes are assumed to have arrived in the order P1, P2, P3, P4, P5, all at time 0.
Draw four Gantt charts illustrating the execution of these processes using FCFS, SJF, a non-preemptive priority (smaller priority number == higher priority), and RR (quantum = 1 and ignoring priority) scheduling. Please follow this format for your answer ('R' is for running, 'w' for waiting):
FCFS:
11111111112222222222
time: 012345678901234567890123456789
------------------------------
P1 RR...(to be continued by you)
P2 ww... "
P3 ww... "
P4 ww... "
P5 ww... "
2.What is the waiting time of each process for each of the scheduling algorithms in part 1?
3.What is the turnaround time of each process for each of the scheduling algorithms in part 1?
4. Which of the schedules in part 1 results in the minimal average waiting time (over all processes)?
B. [2 points] Which scheduling algorithm is provably optimal?
C. [2 points] Which scheduling algorithm has the highest variance in turnaround time in general?
D. [2 points] List the scheduling algorithm(s) which might suffer from starvation.
E. [2 points] Which of these scheduling algorithm(s) require a timer interrupt and preemption for its correct operation?
A. [11 points] Given memory partitions of 370 KB, 220 KB, 550 KB, 120 KB, and 510 KB (in that order), how would each of the first-fit, best-fit, and worst-fit algorithms place processes of 200 KB, 320 KB, 455 KB, 90 KB, and 500 KB (in that order)?
Which algorithm makes the most efficient use of memory? [Note: If there isn't room for a process, simply state it won't fit and must wait.]
End of CS 2200 Homework 3